本文转载自头条号:大数据与人工智能Lab
AlphaGo接近打败了围棋世界冠军李世石、柯洁,震惊世界,掀起了人工智能热潮。围棋界公认AlphaGo的围棋能力已远远超过了人类职业围棋的顶尖水平了,那么AlphaGo为什么这么厉害,它的算法原理是什么呢?
请听我慢慢道来。
一、非AI时代的计算机下棋程序基本做法
在信息完整的情况下,在棋局的每一步,计算机可以使用穷举法,自己与自己下棋(self-play),尝试每一个选择,模拟所有可能的完整战局,观察结果,然后选出最佳走法。
这种方法在五子棋、象棋中还可行,但由于围棋的下子地方很多,各种下棋组合非常的大,穷举法的计算量极其庞大,计算机很难在有效地时间里穷举出最佳走法。

深蓝战胜国际象棋冠军
1997年的“深蓝”计算机战胜了人类的国际象棋冠军卡斯帕罗夫,但是没有人会认为“深蓝”真正拥有了人工智能,这是因为国际象棋的每一步都是可见的。在一个确定性的棋局下,仅有有限个走法,而在这有限个走法中必然有一个最优的,那么一个基本的想法就是对棋局进行预测,遍历(穷举)每一种走法直到一方胜出,然后回退计算每一个可能赢的概率,最后使用概率最高的作为最优的走法。“深蓝”就是这么做的,暴力穷举所有的步子,然后找最优的步子。虽然赢了人类,但没有智能,因为整个算法完全就是按人工设计的一个算法,体现不出智能之处。
计算机下围棋,理论上也是可以暴力破解的,但是问题就在于围棋的可走的步子太多了,以至于按目前的计算性能根本做不到暴力破解。而另外一种方式,是使用蒙特卡洛树搜索的方法,蒙特卡洛算法通过某种“实验”的方法,得到一个随机变量的估计,从而得到一个问题的解。这种实验可以是计算机的模拟,那蒙特卡洛树搜索怎么模拟的。算法会找两个围棋傻子(计算机),他们只知道那里可以下棋(空白处,和非打劫刚提子处),他们最终下到终局。好了,这就可以判断谁赢了。算法就通过模拟M(M>>N)盘,看黑赢的概率。可以看到这明显的不合理,因为每步是乱下的,有些棋根本就不可能。
二、AlphaGo下围棋的原理
AlphaGo下围棋的原理借鉴了专业围棋棋手的思维,也就是俗话说的“走一步、看三步”。首先会先判断在哪几个地方可以下子,胜算比较大;然后在其中某个地方下子后,在脑海中再往后“算”出n步,后面的棋局会是怎么样。
参照这种思维模式,就不用穷举所有的情况了,在AlphaGo里面,针对上面的思维模式,涉及到两个关键动作:(1)棋子要下在哪个位置,(2)推演(“模拟”的方式)在下这一步后,后面几步对方会怎么下。
其中,第(1)关键动作,又可以通过第(2)个动作得来,也就是说AlphaGo在面对当前棋局时,她会模拟(推演)棋局N次,选取N次模拟中某步走法的占比最高,就确定为最优走法。
因此,关键问题在于,AlphaGo是怎么做模拟(推演)的。
模拟就是AlphaGo自己和自己下棋,类似于棋手在脑袋中的推演,就是棋手说的“计算”。
AlphaGo面对当前局面,会用某种策略,自己和自己下,往后下几步或者一直下到终局。
AlphaGo会模拟多次,“不止一次”。越来越多的模拟会使AlphaGo的推演“越来越深”(一开始就一步,后来可能是几十步),对当前局面的判断“越来越准”(根据后面局面变化的结果追溯到前面的局面,更新对前面局面的判断),使后面的模拟“越来越强”(更接近于正解)。
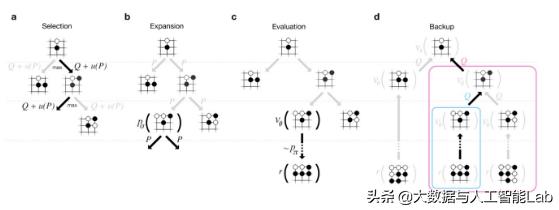
模拟(推演)策略如下:
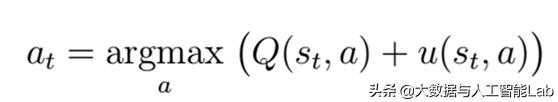
其中,Q代表action value,u代表bonus。
1、Q其实就是模拟多次以后,AlphaGo计算走a这步赢的概率,其中会有对未来棋局的模拟(大模拟中的小模拟)和估计,如下:
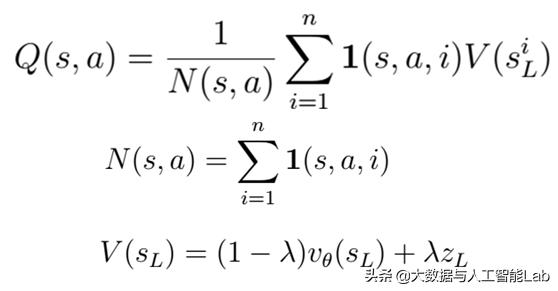
Q看上去有点复杂,但其实就是模拟N次以后,AlphaGo认为模拟这步赢的平均概率。
分母N是模拟这步棋的次数。分子是每次模拟赢的概率(V)的加和。其中,V又包括两部分,value net是对形势的判断,和一个快速模拟到终局,它赢的概率。
2、u中包括两个部分。一方面根据局面(棋形)大概判断应该有那几步可以走,另一方面惩罚模拟过多的招法,鼓励探索其它招法,不要老模拟一步,而忽略了其它更优的招法。
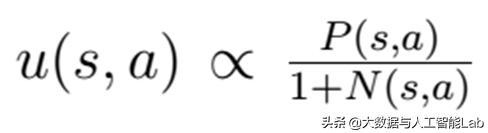
这里u中包括两个部分,分子是AlphaGo根据当前局面判断(policy net),不模拟,比如棋手根据棋形大概知道应该有哪几步可以走;分母是模拟到现在走当前步的累加,越大下次模拟越不会走这了(这里就体现了重复模拟的惩罚)。
因此,(Q+u)就是决定在模拟中,下棋方会走(模拟)哪里。
从上面可以看出AlphaGo的两大神器:value net(形势判断。模拟中,我走这步,我赢的概率是多少)和policy net(选点。模拟中,这个局面我走那几步最强)。
1、第一神器policy net
先看下面这张图。

现在轮到黑棋下,图上的数字是AlphaGo认为黑棋应该下这步的概率。我们还发现,只有几步(2步在这个图中)的概率比较大,其他步可能性都很小。这就像职业棋手了,学围棋的人知道,初学者会觉得那里都可以走,就是policy(选点)不行,没有选择性;而随着棋力的不断增长,选择的范围在不断缩小,职业棋手就会锁定几个最有可能的走法,然后去推演以后的变化。AlphaGo通过学习,预测职业选手的着法有57%的准确率。提醒一下,这还是AlphaGo“一眼”看上去的效果,它没开始推演(模拟)呢。
那么AlphaGo是怎么做的呢?这时就有用到监督学习、深度学习、增强学习等算法了。
(1)监督学习(学习别人的棋谱)
首先,policy net是一个模型。它的输入是当前的棋局(19*19的棋盘,每个位置有3种状态,黑、白、空),输出是最可能(最优)的着法,每个空位都有一个概率(可能性)。着法并非无迹可寻,人类已经下了千年的棋了。policy net先向职业选手学习,她从KGS围棋服务器,学习了3000万个局面的下一步怎么走。也就是说,大概职业选手怎么走, AlphaGo已经了然于胸。学习的目的是,不是单纯的记住这个局面,而是相似的局面也会了。当学习的局面足够多时,几乎所有局面都会了。这种学习叫做“监督学习”(supervised learning)。
(2)深度学习(提升准确性)
AlphaGo强的原因之一是policy net这个模型是通过深度学习(deep learning)完成的,深度学习是近几年兴起的模拟人脑(神经网络)的机器学习方法,它使AlphaGo学习到的policy更加准确。
(3)增强学习(自己跟自己学,生成很多未知的棋局)
AlphaGo从职业棋手学完后,感觉没什么可以从职业棋手学的了,为了超越老师和自己,只能自己左右互搏,通过自己跟自己下,找到更好的policy。比如说,她从监督学习学到了一个policy:P0。AlphaGo会例外做一个模型P1。P1一开始和P0一样(模型参数相同)。稍微改变P1的参数,然后让P1和P0下,比如,黑用P1,白用P0选点,直到下完(终局)。模拟多次后,如果P1比P0强(赢的多),则P1就用新参数,否则,重新在原来基础上改变参数,我们会得到比P0强一点点的P1。注意,选点是按照policy的概率的,所以每次模拟是不同的。多次学习后AlphaGo会不断超越自己,越来越强。这种学习我们叫做增强学习(reinforcement learning)。它没有直接的监督信息,而是把模型放在环境中(下棋),通过和环境的互相作用,环境对模型完成任务的好坏给于反馈(赢了还是输了),从而模型自行改变自己(更新参数),更好地完成任务(赢棋)。增强学习之后,AlphaGo在80%的棋局中战胜以前的自己。
总结一下policy。它是用来预测下一步“大概”该走哪里。它使用了深度学习,监督学习,增强学习等方法。
2、第二神器value net
AlphaGo她的灵魂核心就在下面这个公式里:
V*(s)=Vp*(s)约等于Vp(s)
s是 棋盘的状态,就是前面说的19*19,每个交叉3种状态。
V是对这个状态的评估,就是说黑赢的概率是多少。
V*是这个评估的真值。
p*是正解(产生正解的policy)
p是AlphaGo前面所说学到的最强的policy net。
如果模拟以后每步都是正解p*,其结果就是V*,这解释了等号。
AlphaGo天才般的用最强poilicy,p来近似正解p*,从而可以用p的模拟Vp来近似V*。即使Vp只是一个近似,但已经比现在的职业9段好了。想想她的p是从职业选手的着法学来的,就是你能想到的棋她都想到了。而且她还在不断使得p更准。顶尖职业棋手就想以后的20-40步,还会出错(错觉)。AlphaGo是模拟到终局,还极少出错。
围棋问题实际是一个树搜索的问题,当前局面是树根,树根长出分支来(下步有多少可能性,棋盘上的空处都是可能的),这是树的广度,树不断生长(推演,模拟),直到叶子节点(终局,或者后面的局面)。树根到叶子,分了多少次枝(推演的步数)是树的深度。树的平均广度,深度越大,搜索越难,要的计算越多。围棋平均广度是250,深度150,象棋平均广度是35,深度80。如果要遍历围棋树,要搜索250的150次方,是不实际的。这也是围棋比象棋复杂的多的原因之一。但更重要的原因前面讲了:是象棋有比较简单的手工可以做出的value函数。比如,吃王(将)得正无穷分,吃车得100分,等等。1997年打败当时国际象棋世界冠军的DeepBlue就是人手工设计的value。而围棋的value比象棋难太多了。手工根本没法搞。又只能靠深度学习了。
value net也是一个监督的深度学习的模型。多次的模拟的结果(谁赢)为它提供监督信息。它的模型结构和policy net相似,但是学的目标不同。policy是下步走哪里,value是走这后赢的概率。
总结一下,value net预测下一走之后,赢的概率。本身无法得到。但是通过用最强policy来近似正解,该policy的模拟来近似主变化,模拟的结果来近似准确的形势判断V*。value net用监督的深度学习去学模拟的得到的结果。value net 主要用于模拟(在线,下棋的时候)时,计算Q值,就是平均的形势判断。
再回顾一下模拟,模拟的每一步是兼顾: 模拟到现在平均的形势判断value net, 快速rollout模拟到终局的形势判断, 根据当前形势的选点policy,和惩罚过多的模拟同一个下法(鼓励探索)等方面。经过多次模拟,树会搜索的越来越广,越来越深。由于其回溯的机制,Q值越来越准,下面的搜索会越来越强。因为每次的Q值,都是当前模拟认为的最优(排除鼓励探索,多次后会抵消),模拟最多的下法(树分支)就是整个模拟中累积认为最优的下法。