 人工智能论坛哈萨比斯演讲 人工智能论坛哈萨比斯演讲
5月24日,人工智能高峰论坛在浙江桐乡举行。AlphaGo团队向大家分享技术细节。
 江铸久、芮乃伟、徐莹等棋手与哈萨比斯交流 江铸久、芮乃伟、徐莹等棋手与哈萨比斯交流
各位嘉宾的领域:
刘知青:我们的计算机学院有十年了,祝贺AlphaGo这么快就取得我们以为很久才能实现的成就。我们争取自主研发这些技术并在其他领域里去广泛应用。
周健工:蒙特卡洛搜索树很早就有,为何DeepMind现在能实现这些成就?
刘知青:我认为是数据认识和数据质量上的优化有了飞跃。
李佳:GPU和TPU的出现,信息分享,感兴趣这个领域的人才越来越多,大家添砖加瓦,让人工智能领域得到发展。
陈刚:我觉得需要有百分之二三十人员去实现应用化,比如在医学、教育等领域,其他人去尝试理论上突破。
杰夫迪恩:人工智能和其他领域不太一样,很开放,大家很快出结果发论文,互相阅读交流,在此基础上不断取得新进展。需要不断学习,在很多领域需要机器学习。目前可能仅有一万个公司,我认为至少应该有1500万个公司采用机器学习技术。第二个是,我们需要专业化模型组建,来实现更多功能和目标。
杰夫迪恩:比如在教育领域,我们需要教孩子、测试孩子是否领悟,有点像定制的私教。
刘知青:机器学习有感知、抽象、应用、回馈过程,另外随着机器学习的应用,可以帮助人解脱一定负担,比如计算、检索、记忆等方面,从而可以去做更多创造性的工作,人工智能不是解决人,而是解放了人。
周健工:未来可能是机器智慧与人类智慧相结合,会在哪个领域?
杰夫迪恩:我来讲讲卫生保健。今天的医生经验也是有限的,可能几十年只看了几千病人。而如果把所有医生的经验总结在一起,在看病时给医生提建议,可以有助于医生给病人更好的护理。
李佳:我本来也想说医疗。机器计算力和人的创造力相结合,医生经验和机器数据相结合,医药研发也是很好的例子,并且可以运用到其他行业,比如农业上预测稻谷产量,从卫星云图去发掘天气,再结合人类千年来知识积累,来产生难以想象的结果。
陈刚:个性化教育领域,孔老夫子两千年前就说有教无类,或者说因材施教,但现在实际上还做不到,老师效率还太低,一个班学生很多,很难做到一对一。基于人工智能大数据,有可能实现完全的因材施教。
刘知青:交通物流。我们看到在围棋取得突破性进展,在交通物流方面,怎么能实现资源高效利用率,是人工智能可以突破的方向。
周健工:人工智能能否产生自我意识或自主的动机?
杰夫迪恩:不知道。我们这么多算法就是希望优化人工智能,但不知道能否产生自主的动机。保证安全是第一位的,包括自动驾驶,保证他的行为是按照我们的预期
陈刚:我觉得这是哲学问题了。
周健工:比如AlphaGo可以走出创新的不可预期的一步吗?
杰夫迪恩:AlphaGo可以走出创造性的招法。
李佳:人工智能是实现我们目的的工具,还处在非常早的时期,所以现在提还为时过早。
刘知青:关于自主的动机,目前还看不到,正如李佳所说还处在很早的初期阶段,今后发展还未可知。
第一财经传媒集团CEO周健工:AI在哪些领域应用最多?
圆桌讨论:
周健工:昨天的围棋比赛,看到AlphaGo的胜率曲线一路上升。人工智能在飞速进步,机器智慧是否会超过人类智慧?
北邮教授刘知青:人类智慧与机器智慧是两种不同智慧,不太容易直接比较。比如AlphaGo是以胜率为基础,人类可能是从招法好坏来判断,两者结合可能会发挥更大效果。
谷歌Cloud&AI研发主管李佳:机器和人会发挥各自长处。
浙江大学计算机学院副院长陈刚:机器在运算、记忆等很多方面都很强大,但还需要进一步发展。
谷歌Brain杰夫迪恩:人工智能做翻译还不能取代人类,应用是非常广泛的,机器学习还不能达到人类能力,如果相结合会变得更强大
施密特:在医疗领域可以有很广泛应用,未来5年会带来巨大变化和提升。在中国变化巨大,中文已成为互联网影响巨大的语言之一。iPhone和安卓仅出现十年,现在很难想象离开手机如何生活。我看到最大的变化就是神经网络和深度学习。以前如果程序最开始出错就很难办,现在借助摩尔定律机器变得快多了,机器学习可以自我学习帮助进步。之前我们尝试过很多方式,现在的技术如果在20年前的电脑上运行不了,现在有了第二代TPU等新设备的支持,可以让我们的算法得到很大提升。
如今信息爆炸时代,我们可以通过一些软件工具来帮助管理。现在的科学家已无法读完所有文献,而人工智能可帮助科学家有选择的阅读,与他人异地分享阅读。Tensor Flow可以帮助其他公司,比如BAT公司有上百万用户群,如果用Tensor Flow可以在很多方面有帮助。
人工智能是可以走进寻常百姓家,让更多人受益,并非少数人专属,人工智能可以推动方方面面进步。我们也希望让更多人得到好处。中国也在方方面面飞速发展。人工智能并非会让更多人失业。目前抚养比越来越高,我们希望通过技术来不断调优这个比例。
DeepMind给我的启示是,神经网络等不同领域科学家可以聚到一起,去实现强人工智能。人工智能开启美好未来。多年来我都在想,如果我年轻二三十岁会怎么做,我会加入DeepMind公司。DeepMind在做的,是万里长征第一步。盈利的最重要一步,是在科研、医疗等多个领域通过Tensor Flow来实现。信息安全已不再是技术问题,用加密方式就可以实现。隐私则因国情不同而不同。
周健工:BAT拥有巨量数据和技术,如果将来人工智能推动世界进步,美国五大巨头和中国三大巨头等是否会垄断这种进步?
施密特:我不这么认为。实际上能看到很多新企业家,会不断展现出来,很多领域,包括无人机、医疗等等。我们希望在不同行业践行人工智能优先的原则,可以受益十亿人,我们希望这个愿景可以实现。
Alphabet董事长埃里克施密特:我们以前不清楚柯洁参赛会如何,结果差距非常小,说明柯洁准备充分。我想柯洁也借鉴了AlphaGo的思路和招法,李世石在首尔也试图打败AlphaGo,非常期待明天的第二局比赛。AI对我们的影响越来越大,比如用拍照的方式来帮助翻译,用很小的团队非常少的投入就能实现。
谷歌Tensor Flow已运行两年多,第二代Tensor上周发布,第二代TPU是针对训练及推理设计的,比市面上最好的32台GPU快4倍。TPU舱室有64台第二台TPU,每秒11.5千万亿次浮点运算,内存四百万兆字节,二维环状多跳网络。谷歌向致力于研究开放式机器学习的顶尖研究人员免费开放1000台配有TPU的云虚拟机。
自动化机器学习(学会学习):机器学习模型的设计极其复杂,学会学习,我们能自动解决很多学习问题吗?
现状:模型=数据+计算+机器学习技能(有限供应量阻碍使用量的增长)
方案:模型=数据+100×计算
研究模型,学习优化方程,学习探索方向。
关于智能搜索,未来可查询的问题示例:“哪副眼部图像显示糖尿病性视网膜病变症状”“用西班牙语描述这段视频”“请从厨房为我倒一杯茶”“帮我找出与机器强化学习相关文件并用中文总结一下”。
人工智能有很多可能性,正在产生巨大影响,并且有非常广泛的发展可能。
杰夫迪恩:当我们面对大量照片时,可以自动识别添加标签分类;目前谷歌20%的移动搜索是通过语音完成的;Inbox智能回复中12%的回复是用手机发送的。谷歌图像处理:降噪、消除雨点、栏杆,艺术化处理,明暗识别等等。也应用在谷歌助手里。端到端的信号+人类模仿。使用机器学习改善健康医疗水平。
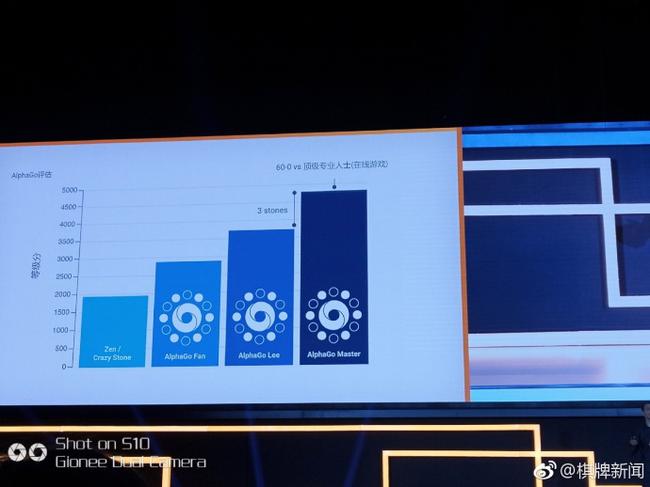 deepmind团队预测,master版本比李世石版本提升了三子 deepmind团队预测,master版本比李世石版本提升了三子
杰夫迪恩:人工智能如何工作。
人工智能创造出智慧的电脑,机器学习创造出会学习的电脑,从而完成伟大的壮举。神经网络是通过不断输入像素等内容参数,根据结果不断来调优,来达到准确的输出结果,培训出模型,直到自己能找到准确答案。包括通过像素识别内容、音频转换文字、翻译、甚至看图来作文。
2011年,神经网络识别图像的错误率是26%,而人类是5%。到2016年,神经网络的错误率已经达到3%,打败了人类,只用了5年的时间。
在学习英语到韩语的翻译时,也同时学习英语到日语的翻译,从而达到更好效果,也自动学会日韩之间的翻译。现在我们有强大计算能力、大量训练数据等从而实现目标。即时相机翻译如何运作?首先拍摄图片找出每个字母再翻译。

大卫席尔瓦:介绍AlphaGo算法。
为什么选择围棋?它是人类最古老、研究最深入的游戏;是构建理解运算的最佳试验台;人工智能面临巨大挑战:游戏大至可以进行穷举搜索。
我们利用卷积神经网络来实现,原版AlphaGo有12层,Master有40层。我们用策略网络和价值网络来解决问题,策略网络进行落子选点,价值网络进行评估。通过人类棋谱来进行监督式学习,调整参数来达到理想效果,通过策略网络来进行强化学习,自我对局成千上万盘,通过价值网络来评估,预测每一步棋后终局的输赢。
如果用穷举搜索,范围实在太大,我们需要简化减少搜索量,通过策略网络来聚焦几个有可能的选项,用价值网络来降低搜索深度。就是AlphaGo的树搜索,从树根开始,一个搜索基础上加上一个新搜索,最终把结果提交给树顶。这个过程会重复成百上千次,直到发现哪一步赢棋概率最高。AlphaGo Lee在谷歌云上有50 TPUs在运作,搜索50个棋步为10000个位置/秒,于2016年在首尔大败李世石。
AlphaGo并不是比深蓝更聪明,而是用价值策略网络减少了搜索范围。AlphaGo Master版本更强大,在单个TPU机器上进行游戏,相当于AlphaGo成为自己的老师,从自己的搜索里学习,使用最好的来自AlphaGo自己的数据;更强大的策略/价值网络。TPU在谷歌云上可供大家使用。
AlphaGo Master强化学习如何实现:AlphaGo与自己对弈,强化学习,自己吸取经验来改进。策略网络P以预测AlphaGo的移动,价值网络V以预测获胜者。比如通过复盘发现那一步是胜招,是第10步,我们通过这样的方式反复迭代,新策略和价值网络用于AlphaGo的下一个迭代中,新版AlphaGo可以得到更好结果和数据,达成良性循环。
AlphaGo的表现如何呢?以围棋等级分来看,以前ZEN、CrazyStone软件达到约2000分,樊麾版AlphaGo达到3000分,李世石版AlphaGo上涨3子,达到3500分,AlphaGo Master又涨3子,达到4500分以上。
DeepMind深度强化学习的目标是:超越AlphaGo。比如在3D射击游戏中,深度强化学习完全通过收到的像素来自我推理学习,达到人类的能力。通过不断学习应对未来的挑战。
 
去年的AlphaGo 与此次AlphaGo 不同之处。

未来能看到人机结合的巨大力量,1+1>2,在AI支持下人类能变得更加强大,有点像哈勃望远镜探索宇宙,人工智能让我们更好了解世界,为人类所用的好工具,在科学、医学等领域帮助人类进步。我们寻求最优,探寻距离最优还有多远,怎样才是完美的棋局;3000年对弈都不足以找到最佳棋局;AlphaGo让我们可以探寻这些有趣奥秘;无数其他领域也将遭遇“组合轰炸”;强人工智能是我们研究和探寻宇宙的终极工具。
在科学研究、新药研制等领域,不仅在玩游戏,也要在现实生活中应用,在数据中心优化方面,我们能节省谷歌中心40%电能。元解决方案:信息过载和系统冗杂是巨大挑战;开发人工智能技术可能是这些问题的元解决方案;目标:实现“人工智能科学家”或“人工智能辅助科学”;和所有强大的新技术一样,在伦理和责任约束中造福人类。我对自己大脑也非常感兴趣,包括如何运作、做梦等等,希望人工智能帮助我们更好了解自己。

哈萨比斯:李世石表示人机大战给了围棋新启发,这令人欢欣鼓舞。关于直觉,就是通过体验直接获得初步感知,但无法言传、表达出来,可通过行为确认其存在和正误。而创造力是通过组合已有知识产生新颖独特想法的能力,AlphaGo显然已在围棋上展现出了创造力。我们希望打造完美的AlphaGo。在首尔的比赛显示AlphaGo还有不足,我们希望弥补他的空白,在网上以Master的名字来做测试,获得60比0的佳绩,棋手们获得很多启发。展现出很多新招法,比如点三三、序盘连续爬二路,等等。柯洁表示人与AI应携手并进,古力也表示人与AI合作的时代大幕已拉开。卡斯帕罗夫也在书中说,深蓝已结束,而AlphaGo才刚开始。AlphaGo有点像吴清源在三四十年代一样带来围棋新时代。棋类程序讲战术,而AlphaGo讲战略。
 哈萨比斯回顾去年与李世石的比赛 哈萨比斯回顾去年与李世石的比赛
戴密斯哈萨比斯:今天我将介绍如何赋予机器创造力,以及DeepMind在做什么。DeepMind2010年创立于伦敦,2014年加入Google,目前进行人工智能“阿波罗计划”,发现研发科学新方式。我们第一步是要攻克智能。打造通用型学习机器,非程序预设——自主学习原始材料;通用:同一系统可执行多种任务。用原先的经验应对新挑战。核心技术是深度学习和强化学习。
通用型的强人工智能与弱人工智能不一样。最好的例子就是深蓝击败卡斯帕罗夫,智能之处是用既定代码输入深蓝,还不算强化学习。
强化学习框架:智能体通过观察建模来了解环境,从而做决定计划行动,应对挑战,强人工智能就能实现,从而帮助到人。
雅达利智能体:包括百余款八十年代的八位雅达利游戏。通过深度强化学习,在进行300次游戏后发现捷径明显变得更加善于游戏,获得更好策略,这是三年前的情况。
这两年AlphaGo团队专注于围棋项目,因围棋复杂程度让穷举搜索都难以解决:“不可能”写出评估程度已决定谁赢;搜索空间太过庞大。
围棋与国际象棋相比,不光是简单计算,更需要直觉。比如问国象棋手,他会说自己有明确的逐步计划。而围棋手可能不仅靠计算,而是靠直觉;围棋中没有等级概念,所有棋子都一样;棋盘是空的,要在心中不断摸索预测未来,围棋是建筑游戏,因此需要盘算未来;小小一子可撼全局,牵一发而动全身;“妙手”如受天启,玄妙深奥,好像天赋灵感。
如何才能化繁为简,是通过两种网络来实现:策略和估值网络。我们在《自然》杂志发表论文,很多公司也随之作出了很不错的人工智能围棋程序。去年AlphaGo与李世石的人机大战令韩国万人空巷,AlphaGo最终获胜,这一刻等了十年,可以说是十年磨一剑。在第二局中,AlphaGo第37步棋是我最喜欢的,让世人惊叹,他走出五路尖冲,是让人难以想象的。如果在三路是重视实地,在第四路下棋更重视中央,而在第五路下棋则很少,似乎有些落空的感觉,自古人类都低估了在五路下棋的价值。而AlphaGo左下早早的两颗黑子在50步后发挥出了作用。而李世石在第四局走出的那一手也显示出他的天才,那次人机大战有2.8亿观众、3.5万篇报道、棋盘销量增长10倍。

上台前的哈萨比斯,今天他会和大家分享些什么呢?
 参加论坛的樊麾和黄博士 参加论坛的樊麾和黄博士
|